The Mirage of the Cloud: The Costs of Convenience

Our data floats in their cloud
Series: From Cloud Insecurity To Local Sovereignty
Thesis: Cloud AI feels limitless—until you examine what it really costs in money, energy, and autonomy. This post helps readers uncover the hidden dependencies behind cloud computing and introduces practical methods for measuring their true “cloud tax.”
Reader Level: Practitioner
Reading Time: ~10 minutes
When Scale Feels Free
Over the last fifteen years, “the cloud” has become a metaphor for freedom. It suggests something vast, weightless, and always available—an invisible utility that powers the modern internet. Businesses and creators alike have come to treat it as the natural home for computation, from streaming video to fine-tuning large language models.
Yet what feels like liberation often hides a subtle trade-off: we gain access by surrendering visibility. When your compute, storage, and even AI inference live behind managed dashboards, the complexity appears to vanish. You stop thinking about the hardware, the energy, or the ownership of your data. The friction disappears, but so does the understanding.
This is the first essay in the “From Cloud to Local AI” series by Companion Intelligence. Each post explores a step in the journey from dependency on centralized infrastructure toward confidence in local systems—without ideology or alarmism. We begin with the seductive story that started it all: the cloud as a miracle of scale and simplicity. Beneath that promise lies a set of very real costs that every responsible technologist should understand before building the future.
The Seduction of Infinite Scale
Cloud marketing sells a feeling more than a feature: infinite reach without friction. The interface looks like a blank canvas, the billing like pocket change per hour. Behind that elegance sit networks of real metal, real power draw, and real contracts—each quietly tallying cost and dependency.
When we stop seeing the machine, we stop questioning its appetite. The illusion of abundance is maintained by distance; servers hum in another country, invoices arrive weeks later. That distance is profitable for someone, but disorienting for you.
Goal: Recognize how the promise of limitless, frictionless computing conceals real financial, environmental, and human costs—and how measuring them restores perspective.

Our Budgets—and Data—Fuel Their Profits.
Clouded Promises & Obscured Intentions
Cloud marketing rests on a simple emotional appeal: you can have everything, instantly, without ownership or risk. Pay-as-you-go pricing and “serverless” architectures seem to erase the need for infrastructure decisions. A developer can deploy an entire AI service before lunch and scale it to millions of users by dinner.
But the fine print tells a different story. Every image rendered, dataset transferred, or model called across regions carries a metered cost—tiny on its own, enormous in aggregate. What begins as experimentation often grows into dependency.
When a small studio ran Stable Diffusion on AWS for a week, the bill exceeded $500, mostly due to GPU instance costs and egress fees—the charges for pulling data out of the cloud. That’s the “slow burn” researchers at DatacenterDynamics describe as a structural lock-in mechanism, multiplying migration costs over time.
Academic studies confirm this pattern. A 2024 CMJ Publishers review found that security compliance, data egress, and managed service premiums together can increase total ownership costs by up to 70 percent compared to local deployments. The Nanyang Technological University paper Towards Pay-As-You-Consume Cloud Computing showed that usage-based billing is volatile and unpredictable under real workloads.
The illusion of frictionless scalability masks a deeper asymmetry: the provider controls the meter, not the user. When the only visible number is the monthly invoice, you lose the feedback loops that teach efficient design.
Example of Cloud Costs:
Measuring the True Cost of a Week of AI Inference:
Imagine running Stable Diffusion XL for a creative sprint.
You spin up a single AWS g5.xlarge instance (A10G GPU, 4 vCPUs, 16 GB RAM).
One click—seemingly harmless—starts a silent meter.
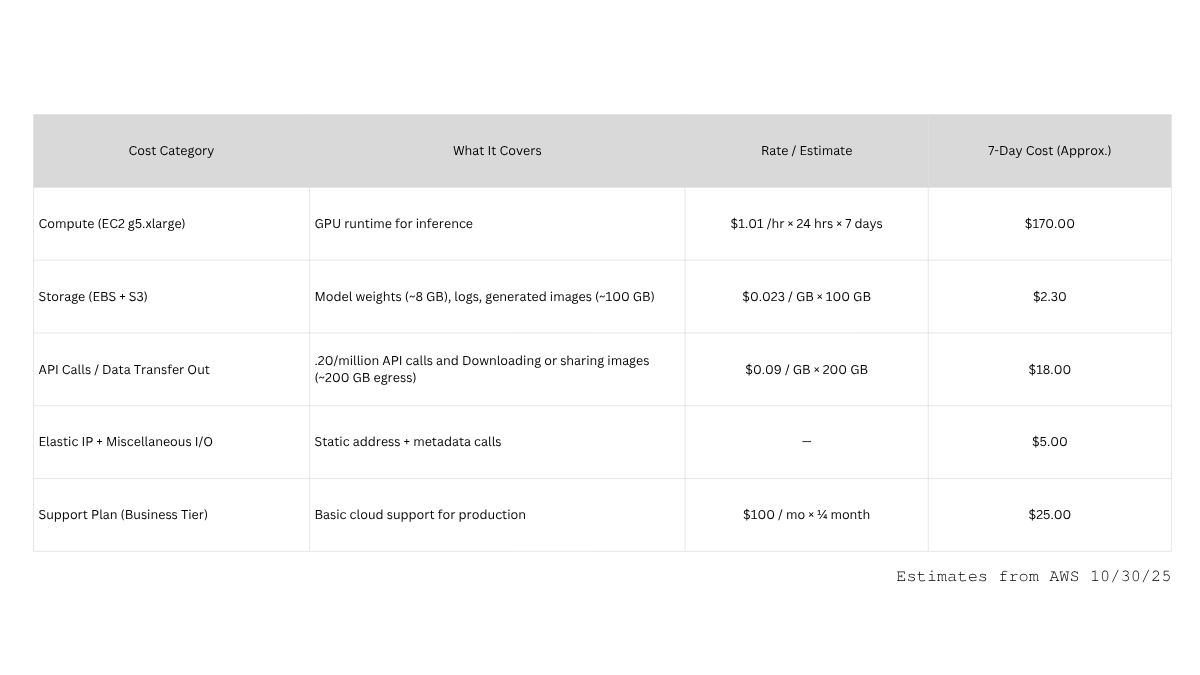
Estimated Total: ≈ $220–$250 for one week
On A Local Workstation:
A mid-range desktop drawing ~300 W, running eight hours a day for seven days, consumes roughly 17 kWh (~$3–$5 of electricity weekly).
Storage is local, and there are no egress fees or API mark-ups.
Comparing Cloud Versus Local Options
The cloud appears inexpensive per hour, but hidden layers—data transfer, support, and persistent storage—turn short-term testing into long-term spending.
For readers without hardware access, similar transparency comes from open-source calculators such as Infracost or from community labs that publish cost-per-task metrics. What matters is visibility, not ownership—seeing where energy and money flow.
Try it yourself:
Use AWS Pricing Calculator or Infracost CLI to model each cost component.
Include compute, storage, data transfer, and support lines.
Record both hourly and monthly projections to visualize how “experimentation” becomes recurring cost.
When you translate abstract pricing into tangible numbers, the cloud stops feeling infinite—it becomes measurable, understandable, and something you can choose deliberately.
Reflection · The Human Angle
Where does convenience in your workflow shift from empowerment to dependence? What part of your creative or analytical process could live closer to you—on your desk, in your office, or in your community cloud?
The Hidden Architecture of Dependence
Dependence in technology rarely comes from ignorance; it comes from design. Each major provider—AWS, Microsoft Azure, and Google Cloud—builds what scholars call infrastructural ecosystems: vertically integrated stacks where compute, storage, machine learning, and analytics are optimized to work best together, and only together.
D. Luitse’s 2024 paper Platform Power in AI describes this as a deliberate concentration of “infrastructural power”—a condition where the tools for innovation themselves become governed by a few platforms. Once you rely on their proprietary APIs and SDKs, every project incrementally aligns to their logic.
Cloud-native AI services such as SageMaker, Vertex AI, and Azure OpenAI illustrate the pattern. They simplify pipeline management but enforce platform-specific formats for model deployment, dataset ingestion, and authentication. Switching to an alternative means rewriting code, re-training models, and re-configuring compliance.
Santa Clara University’s Multi-Cloud API Approach demonstrated that API abstraction layers can mitigate this risk, but also increase complexity and latency. Similarly, the International Journal of Innovative Research in Technology found that multi-cloud strategies often shift, rather than solve, dependency—introducing new failure points and higher cognitive load for teams.
In short, the convenience of managed services trades local flexibility for institutional inertia. The longer you stay, the harder it becomes to leave.
Practice:
Map your current workflow on paper. Circle every process that depends on a proprietary tool or API. Could you replicate it with open-source frameworks like Ollama, ComfyUI, or LM Studio? The goal is not replacement but recognition—seeing where your autonomy ends.
Reflection:
If your primary provider doubled prices tomorrow, how much of your system could you realistically migrate in 30 days?
The Real Price of Abstraction
Goal: Understand the environmental and cognitive costs of offloading control.
Abstraction is one of computing’s greatest achievements. It allows us to focus on outcomes instead of implementation. But as with any abstraction, what disappears from view can also disappear from concern.
In the cloud, every inference request, every storage transaction, and every batch job draws energy somewhere far away—out of sight and out of accountability. The International Energy Agency’s 2025 critical review found that global data-center energy demand has become both enormous and under-reported because hyperscale operators do not disclose detailed infrastructure data.
At MIT, researchers summarized the issue simply: cloud AI’s environmental cost is immense and largely invisible to end-users. One peer-reviewed study benchmarked inference energy for large language models across both local and cloud scenarios. Per-query efficiency favored the cloud, but aggregate usage produced far higher total emissions due to global query volume.
Abstraction hides not only energy but learning. When developers deploy through APIs, they lose the tactile knowledge of tuning performance, managing memory, or optimizing batch size. Those skills matter for efficiency and sustainability alike.
Energy awareness is a form of literacy. Knowing how many watts your model consumes grounds innovation in reality. Local inference doesn’t automatically mean greener—but it does make the cost visible, and visibility invites accountability.
Example: Seeing the Wattage Behind the Prompt
A mid-range GPU drawing 300 watts for one hour performs roughly 2 billion tokens of inference at about 0.3 kWh. At $0.30 per kWh, in California, that’s nine cents.
A similar session via API might bill $1 or more once latency, data transfer, and service fees layer in—ten times the energy and economic cost once amortized through infrastructure and profit margins.
For teams without local hardware, shared community compute—co-ops, universities, or public innovation hubs—offers a middle path: transparent metering, visible power use, and collaborative stewardship.
Practice: Make the Invisible Visible
Measure: Run a local inference and note your GPU’s watts (using vendor tools or a smart plug).
Estimate: Multiply by hours per week → kWh.
Compare: Look up the same model’s API pricing and published energy averages (IEA 4E, MIT).
Reflect: Decide where performance justifies outsourcing and where ownership builds skill.
Key Takeaway: Energy awareness is technical literacy and ethical practice in the same gesture.
Reflection:
If you could see the kilowatt-hours behind your creative work, what values might guide your next architectural decision?

Reclaiming Visibility and Agency
Goal: See how small, deliberate shifts—from blind dependence to transparent practice—can restore technical confidence, privacy, and shared responsibility.

Agency begins with visibility. You cannot control what you cannot see. The modern AI landscape often encourages dependence by abstracting away both data handling and decision-making.
A 2025 ACM Digital Library study, The Privacy Paradox of Large Language Models, found that local inference grants users far greater control over personal information flows than cloud-hosted APIs. Locally deployed models keep sensitive prompts, logs, and embeddings under direct ownership, reducing exposure to opaque provider data policies.
In high-stakes environments—medicine, law, education—this visibility is not optional. Research from Imperial College London demonstrated that running models locally allowed biomedical teams to meet regulatory requirements while retaining fine-grained auditing and customization.
The University of South Florida’s guide Self-Hosting AIs for Research takes the concept further: local deployment enhances technical literacy. By handling installation, updates, and resource monitoring, users gain an understanding of how inference actually works. That understanding is empowerment—it transforms AI from a black box into a craft.
Reclaiming agency doesn’t require rejecting the cloud. A balanced practice combines local control for privacy and experimentation with cloud capacity for burst demand. Hybrid architectures mirror the hybrid nature of human work: sometimes distributed, sometimes focused.
Practice:
Choose one model under 10 billion parameters—Mistral 7B, Phi-3 mini, or Gemma 2B.
Run it locally using Ollama or LM Studio.
Monitor your GPU, CPU, and energy use while prompting.
Compare performance, cost, and privacy benefits against a cloud API equivalent.
Stay tuned for more series from Companion Intelligence where we will be sharing ticks and tips from the studio to help you get to the next level in you #goLocal goals.
Documenting your current process will reveal where you depend on the cloud and where you don’t need to.
Reflection:
What would it mean for your professional confidence if your tools lived close enough to touch?
How might shared infrastructure—community clouds, co-ops, research hubs—turn personal control into collective strength?
Seeing Through the Mirage
Academics, small businesses, and especially the creative community are withstanding enormous pressures.
By now, the “mirage” of the cloud comes into focus. The convenience was real—but so were the hidden costs. The path forward isn’t just to withdraw; but to go forward with intentionality.
Imagine returning to that original cloud experiment—Stable Diffusion on AWS—but this time with insight. You host your model locally for routine tasks, leveraging the cloud only when you genuinely need scale. Your expenses drop, your latency improves, and you understand every step of your pipeline.
This is the mindset shift the industry quietly needs: from frictionless consumption to mindful computation. We cannot manage what we cannot see, and we cannot steward what we do not understand.
Practice:
Set one achievable goal this month: migrate a small workflow, dataset, or model to local inference. Observe not just the performance metrics but your own sense of control and curiosity.
Reflection:
What new freedom emerges when you own not just your compute, but your relationship to it?
If knowledge is shared and responsibility distributed, could technology become a commons rather than a commodity?
Owning the Means of Computation
The cloud’s genius lies in abstraction. The cloud made computing accessible. But abstraction without accountability breeds dependency. By examining the true costs of convenience—financial, structural, and ecological—we can design more responsible systems.
Local AI does not replace the cloud; it restores balance. It reconnects people with the material reality of their tools. As you continue through this series, remember that awareness itself is a tool. Honing your networking literacy is the first step to data-sovereignty.
The next essay, “The Return of the Local,” explores how communities and organizations can share infrastructure responsibly to sustain both innovation and autonomy.
Series: From Cloud to Local, 25-001
Citations & References
Abhishek, & Siwach, V. (2023). Evaluating vendor lock-in and service availability risks in multi-cloud deployments. International Journal of Innovative Research in Technology. https://ijirt.org/publishedpaper/IJIRT180346_PAPER.pdf
Barbosa, L., et al. (2012). Impact of pay-as-you-go cloud platforms on software pricing and development. Universidade Federal de Santa Maria (UFSM). https://www.ufsm.br/orgaos-suplementares/cpd/wp-content/uploads/sites/350/2018/07/ICCSA2012_CameraReadyBarbosa.pdf
Chen, A., Kathika, J., & Ngo, K. (2021). Multi-cloud API approach to prevent vendor lock-in. Santa Clara University, Department of Computer Science and Engineering. https://www.cse.scu.edu/~m1wang/projects/Cloud_preventVendorLockIn_21w.pdf
Chen, S., Birnbaum, E., & Juels, A. (2025). SoK: The privacy paradox of large language models. Cornell Tech, Johns Hopkins University, New York University, & ETH Zurich. ACM Digital Library. https://dl.acm.org/doi/10.1145/3708821.3733888
DatacenterDynamics. (2024). The slow burn of data egress fees. https://www.datacenterdynamics.com/en/analysis/the-slow-burn-of-data-egress-fees
International Energy Agency. (2025). Data centre energy use: Critical review of models and results. Energy Efficient End-Use Equipment Programme (4E). https://www.iea-4e.org/wp-content/uploads/2025/05/Data-Centre-Energy-Use-Critical-Review-of-Models-and-Results.pdf
Ibrahim, S., & He, B. (n.d.). Towards pay-as-you-consume cloud computing. Nanyang Technological University & Huazhong University of Science and Technology. https://www.comp.nus.edu.sg/~hebs/pub/shaditowardscc11.pdf
Jegham, N., Abdelatti, M., Elmoubarki, L., & Hendawi, A. (2025). How hungry is AI? Benchmarking energy, water, and carbon footprint of LLM inference. University of Rhode Island & University of Tunis. arXiv preprint. https://arxiv.org/html/2505.09598v1
Luitse, D. (2024). Platform power in AI: The evolution of cloud infrastructures in the political economy of artificial intelligence. Internet Policy Review. https://policyreview.info/articles/analysis/platform-power-ai-evolution-cloud-infrastructures
MIT News. (2025). Explained: Generative AI’s environmental impact. MIT Schwarzman College of Computing. https://news.mit.edu/2025/explained-generative-ai-environmental-impact-0117
Plantin, L., & Helmond, D. (2024). Platform power in cloud computing: The case of AI. In Data practices: AI and the politics of data infrastructures. Amsterdam University Press. https://www.aup.nl/en/book/9789463721919/data-practices
Rajendran, V., Kumar, K., & Singh, S. (2025). Comparative analysis of energy reduction and service-level agreement compliance in cloud and edge computing: A machine learning perspective. International Journal of Energy Research. https://onlinelibrary.wiley.com/doi/10.1002/er.6723
ScienceDirect. (2022). User preferences on cloud computing and open innovation. Procedia Computer Science. https://www.sciencedirect.com/science/article/pii/S219985312200436X
University of South Florida Libraries. (2023). Self-hosting AIs for research: AI tools and resources. https://guides.lib.usf.edu/AI/selfhosting
World Journal of Advanced Research and Reviews. (2024). Green cloud computing: AI for sustainable database management. https://wjarr.com/sites/default/files/WJARR-2024-2611.pdf
Zha, S., Rueckert, R., & Batchelor, J. (2024). Local large language models for complex structured tasks. Imperial College London, University of Manchester, & Technical University of Munich. PubMed Central.https://pmc.ncbi.nlm.nih.gov/articles/PMC11141822