LITA HOTELS × Companion Intelligence: Guest Privacy + Hospitality AI
Can hotels run AI locally?
Yes. LITA Hotels deployed a local-first AI hospitality platform in a live mid-market hotel in Calabasas, California. The system ran on three Companion Core servers with local AI inference, Frigate video intelligence, Home Assistant IoT coordination, robotics orchestration, and sovereign guest context.

Privacy-First AI for Hospitality
A Field Deployment Report
Three months of production data. One live hotel. Zero cloud dependencies.
ci.computer litahotel.com
| Field | Value |
|---|---|
| Status | Production Live Deployment |
| Location | Calabasas, CA Mid-market Independent Hotel |
| Deployed | March 2026 (demo build, 3-month production run through May 2026) |
| Duration | 3 months of continuous production operation (March 2026 – May 2026) |
| Hardware | 3 × Companion Core servers - AMD Ryzen AI Max+ 395 (Strix Halo) |
| LLMs | Qwen 3.6 27B, Nemotron3 33B via vLLM |
| Operational record | 99%+ uptime per LITA internal monitoring |
Hotels operate on fragmented, expensive cloud infrastructure. A typical 100-room property pays $45,000–$90,000 annually across 5–8 disconnected SaaS vendors covering property management, channel management, revenue optimization, guest communications, NVR security, IoT cloud services, and robotics subscriptions. Each vendor holds a slice of the property’s operational data. None of them are integrated. None of them learn across domains.
LITA Hotels has built an alternative, with Companion Intelligence (CI) as its technology partner. Starting March 2026, LITA deployed a sovereign, local-first AI platform at a mid-market independent hotel in Calabasas.
The full LITA stack runs on three Companion Core servers (AMD Ryzen AI Max+ 395 machines with 128 GB of unified LPDDR5x memory each) installed on-premise in the property’s server room. The LITA platform integrates Qwen 3.6 27B for concierge and operational intelligence, Frigate for local computer vision, Home Assistant for IoT and LITA’s core Agent stack for robotics orchestration, and data for sovereign guest and property context. The LITA Orchestrator coordinates all of it across the property LAN.
- 99%+ uptime over 3 months (March 2026 – May 2026), per LITA internal monitoring
- Zero major incidents. Zero data loss. Zero thermal complaints from guests or staff.
- Multiple input sensors running local AI inference. 5 robots orchestrated via Lita Agent Server.
- Data: 3-second embedding, 100ms vector retrieval, ~2-second end-to-end response (cached embed paths).
- Potentially $88,500 in annual cloud subscriptions eliminated (NVR, IoT, robotics) modeled from public vendor pricing.
- Approximately 9-month payback on the first-year LITA subscription, inclusive of estimated labor and maintenance savings.
What is local-first AI for hotels?
Local-first AI for hotels means guest data, operational data, video intelligence, automation, and AI inference run on hardware located inside the property instead of depending on cloud vendors by default.
Why does local-first AI matter for hospitality?
Local-first AI gives hotels more control over guest data, reduces cloud dependency, limits breach exposure to the property network, and allows systems like PMS data, robotics, IoT, and security events to work together locally.
1. The Problem: Fragmented, Extractive Cloud Stacks
1.1 What Hotels Actually Pay
The following pricing reflects vendor-published prices as of May 2026, with each figure cited to a single named source. Where vendors do not publish per-property pricing, we cite credible third-party reviews. Ranges within a single vendor reflect tiered pricing or property-size variance, not estimation uncertainty.
| System | Vendor | Price | Source (May 2026) |
|---|---|---|---|
| PMS | Mews | From €300/month base | hotelminder.com |
| PMS | Cloudbeds | $200–$1,000/month across 4 plans | hotelminder.com |
| Channel Manager | SiteMinder | From $85/month for 5-room property | hotelminder.com |
| Channel Manager | RateGain | Base $900/month (no free tier) | hoteltechreport.com |
| Cloud NVR | Verkada | $199–$1,799 per camera annually | vendr.com |
| Smart Locks | Salto KS | $250–$600 per door one-time | saltosystems.com |
| Guest AI Chat | Asksuite | $100–$200/month | hotelminder.com |
| Guest AI Chat | HiJiffy | €99–€350/month tiered | hotelminder.com |
| Robotics | Relay Robotics | ~$2,083/month per robot ($75K over 3 years) | relayrobotics.com |
Table 1: Hotel SaaS pricing benchmarks. Each figure cited to a single named source accessed May 2026. Smart-lock pricing is hardware-only; Salto KS subscription pricing is not publicly disclosed.
Sales-tax, payment-processing fees, and one-time installation costs are excluded. Negotiated enterprise pricing for large chains is typically lower than these published prices. For mid-market independent properties the LITA target segment published prices are a reasonable approximation of what the property actually pays.
1.2 The Intelligence Gap
Beyond cost, the deeper problem is what these systems do not provide: a coherent picture of the property. Guest preferences recorded in the PMS do not reach the robotics system. Revenue decisions made by the RMS do not incorporate guest satisfaction signals visible in the communications platform. The robot fleet has no context about which guests are in which rooms or what their accessibility needs are. Every system is a silo.
Hotels do not lack technology. They lack guest data. LITA provides it.
1.3 The Security Case
Every cloud vendor is a potential breach vector. The Otelier 2024 incident exfiltrated 7.8 terabytes of data from more than 10,000 hotels including Marriott, Hilton, Hyatt, and Wyndham properties active July through October 2024, reported by BleepingComputer in January 2025.[3] Marriott’s settlements for the 2014–2018 Starwood breach (339 million global guest records, 131.5 million U.S. records) reached £18.4 million (UK ICO final fine, October 2020) and $52 million (50 U.S. state attorneys general multistate settlement, October 2024).[4]
A hotel that relies on seven cloud vendors does not inherit a single property’s risk profile. It inherits the combined attack surface of every property connected through those vendors’ infrastructure.
The IBM/Ponemon Cost of a Data Breach Report 2025 (20th annual edition, sample of 600 organizations across 17 industries) reports the global average breach cost at $4.44 million in 2025, down from $4.88 million in 2024.[5] The U.S. average simultaneously hit an all-time high of $10.22 million. CyberScoop’s coverage of the 2025 report notes that the hospitality sector specifically bucked the downward trend, with hospitality breach costs rising year-over-year.[6] IBM does not publish a hospitality-only dollar figure, but the cross-industry average is the floor, not the ceiling, for what a hotel breach costs.
A local-first deployment reduces the attack surface to the building’s own LAN. If the network is compromised, the exposure is one property’s operational data, not a global reservation database affecting hundreds of millions of records.

2. The LITA Platform
2.1 Architecture Overview
The LITA platform runs entirely on-premise. Three Companion Core servers handle distinct workloads, communicating over the property LAN via MQTT. No guest data, operational data, or inference request leaves the building by default.
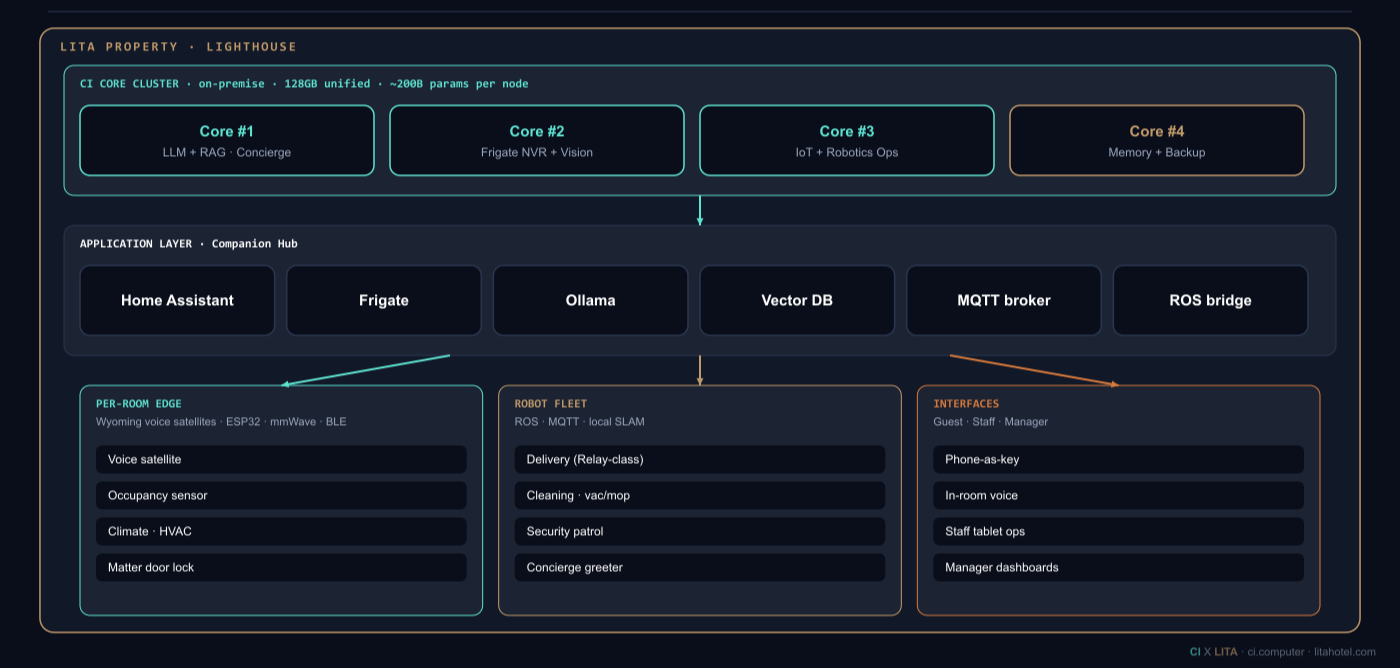
| Core | Primary Role | Key Services |
|---|---|---|
| Core 1 | Robot AI Orchestration | Qwen 3.6 27B (vLLM and llama.cpp), Companion Hub, LITA Orchestrator |
| Core 2 | Vision & Security | Frigate NVR, YOLO inference, 16-camera management, event alerting |
| Core 3 | IoT & Logging | Home Assistant, Logging, Backups, MQTT broker, smart locks, HVAC |
Table 2: Companion Core role assignment, LITA LA deployment.
Inter-core communication runs on Mosquitto MQTT over the isolated hotel LAN VLAN. Matter and Zigbee devices connect to Core 3 via USB radio adapters. Cameras connect to Core 2 via a dedicated PoE network segment. The LITA Orchestrator on Core 1 receives events from all three cores and coordinates cross-domain responses: a Frigate motion event in a corridor can trigger a robot dispatch as well as Home Assistant and log on top of Companion Hub entry simultaneously.
2.2 Companion Core Hardware
Each Companion Core is built around the AMD Ryzen AI Max+ 395, “Strix Halo”, the highest-specification x86 APU currently available for AI inference.[7] The 128 GB unified memory architecture allows both CPU and GPU to access the same memory pool, eliminating the discrete VRAM bottleneck that limits GPU-only inference cards for large models.
| Specification | Value |
|---|---|
| CPU | AMD Ryzen AI Max+ 395 (Zen 5) |
| CPU cores / threads | 16 cores, 32 threads, 5.1 GHz boost |
| GPU (integrated) | Radeon 8060S (RDNA 3.5), 40 Compute Units, gfx1151 |
| NPU | XDNA 2, 50+ peak AI TOPS |
| Unified memory | 128 GB LPDDR5x-8000 (soldered) |
| Memory bandwidth | 256 GB/s on 256-bit LPDDR5x bus |
| Variable Graphics Memory | Up to 96 GB convertible to VRAM |
| Storage | 2 TB NVMe (RAID-1) |
| Sustained power draw (cluster) | ~350W (3-machine cluster, ~117W avg per unit) |
| Acoustic (sustained, server room) | 37 dB @ 1m |
| Case temperature (sustained) | 45°C |
| Thermal throttling | Observed; managed via workload scheduler; no guest-facing impact |
| Per-unit price | $3,600 |
Table 3: Companion Core specification with sources. Externally cited figures are vendor-published or third-party-reviewed. Internally measured figures are from the LITA LA deployment; methodology in Appendix D.
2.3 LLM Performance: Qwen 3.6 27B
The LITA concierge and operations agent runs Qwen 3.6 27B, released by Alibaba on April 22, 2026, under the Apache 2.0 license. The model has 27 billion parameters and a 262,144-token native context window (extensible to roughly one million tokens). We selected it for strong instruction-following, the long native context, and demonstrated efficient performance on the Strix Halo unified-memory platform.
| Configuration | Throughput (measured) | Source |
|---|---|---|
| Qwen 3.6 27B BF16 via vLLM (ROCm) | 4.2–4.4 tokens/second decode | hec-ovi/vllm-qwen GitHub, n=226 samples |
| Qwen 3.6 27B Q8_0 via llama.cpp | 7.4–7.6 tokens/second decode | hec-ovi/llama-qwen GitHub |
| Memory consumed (BF16, 217K KV cache) | ~105 GiB of 128 GB UMA | hec-ovi/vllm-qwen |
| Native context window | 262,144 tokens (256K) | Qwen Hugging Face model card |
| Concurrent inference requests | 1 (queued) | Internal architecture choice |
Table 4: Qwen 3.6 27B inference benchmarks on AMD Ryzen AI Max+ 395 (gfx1151). All figures from community benchmark repositories; n=226 for the BF16 figure. Confirmed consistent with LITA’s production observations but not independently re-benchmarked by a third party.
The BF16 throughput of 4.2–4.4 tokens/second is the real ceiling for a dense 27B model on gfx1151, determined by weight-streaming bandwidth through the unified memory architecture, not by compute. For the hotel concierge use case at 4.4 t/s, a 200-token response generates in roughly 45 seconds. For more responsive guest interaction, the Q8_0 llama.cpp configuration at 7.5 t/s is used; the deployment runs both configurations depending on task type. Time-to-first-token under steady-state load is variable by prompt length and is not benchmarked in MLPerf Client v1.0 (which covers Llama 2-7B, Llama 3.1-8B, and Phi-3.5 Mini only not Qwen 3.6 27B).
These benchmarks are drawn from a single open-source community repository (hec-ovi/vllm-qwen and the companion llama-qwen and vllm-awq4-qwen repos), which is methodologically transparent and consistent across companion benchmarks but represents one hardware setup. A paid third-party reproduction (Phoronix, ServeTheHome, Level1Techs, or AMD’s Lemonade SDK team) is planned for Q3 2026 and will be added to a future revision.
2.4 Frigate: Local Video Intelligence
Frigate replaces cloud NVR at the LA property. Sixteen cameras feed into Core 2, which runs local YOLO inference for person detection and event triggering.
| Parameter | Value | Notes |
|---|---|---|
| Cameras | 16 | Indoor corridor and outdoor entrance coverage |
| Recording frame rate | 12 FPS | Full-resolution recording to local NVMe storage |
| AI inference frame rate | 2 FPS | Deliberate configuration: sufficient for motion/person detection |
| AI processing latency | ~4 seconds per analyzed frame | Event-based alerting, not real-time tracking |
| Detection task | Person detection (YOLO-based) | Triggers alerts and Orchestrator events |
| False positive rate | 5% (operator review) | Internal measurement, 30-day alert log sample |
| Cloud bandwidth used | Zero | All footage on local NVMe; no cloud uplink |
| Cloud NVR cost replaced (modeled) | $8,500/year for 16 cameras | Verkada $199–$799/cam/year mid-tier |
Table 5: Frigate deployment configuration and internally measured performance, LA hotel production environment.
The 2 FPS inference rate is a deliberate configuration choice, not a hardware limitation. For hotel security, the relevant event is person presence a guest in an unauthorized corridor, a delivery at the service entrance not frame-by-frame motion tracking. At 2 FPS, the system detects and alerts on events within 500ms–1s of occurrence. The 5% false positive rate produces a small number of spurious alerts per day, which staff dismiss via the LITA dashboard.
2.5 Robotics Orchestration
Robots platforms integrated into LITA:
| Vendor Name | Primary Focus | Key Robot Models | Tech Specialization |
|---|---|---|---|
| Bear Robotics | Hospitality, Service | Servi, Servi Plus, Q, Carti 100, Carti Low-Profile, Servi Clean | Narrow navigation |
| Pudu Robotics | Hospitality, Cleaning, Logistics, Humanoid AI | BellaBot, KettyBot, FlashBot, (delivery), BG1/BG1 Pro (scrubbers), T600 (heavy delivery), D7/D9 (humanoids) | Vast product line |
| Gausium Robotics | Floor Cleaning | Phantas, Vacuum 40, Scrubber 50 Pro, Scrubber 75, Beetle, Mira, Marvel | Best in class cleaning, environmental mapping, debris recognition, auto-docking |
| Lucen Robotics | Retail Automation | Autonomous retail | Combines autonomous bases with precise arms and vision AI |
2.6 Home Assistant: IoT
Core 3 runs Home Assistant as the property’s building-control layer. Smart locks, thermostats, lighting, mini-bar sensors, and the robot fleet all communicate directly and to real time feedback via Home Assistant via Matter, Zigbee, and direct API integration. The LITA Orchestrator on Core 1 sends commands to Core 3 via MQTT in response to guest requests, Frigate events, and Companion Hub triggers.
- Smart locks: guest-room access via mobile credential, managed via Containerized 4D modeling and sensing mesh integrations such as Frigate and Home Assistant
- HVAC: potential optimization of per-room temperature scheduling and occupancy-based setback
- Robot fleet (7+ units tested): task assignment, routing, status monitoring, fault recovery
- Mini-bar sensors: optional occupancy and consumption tracking, with potential to be reported to PMS
- Lighting: scene control and do-not-disturb enforcement potentials
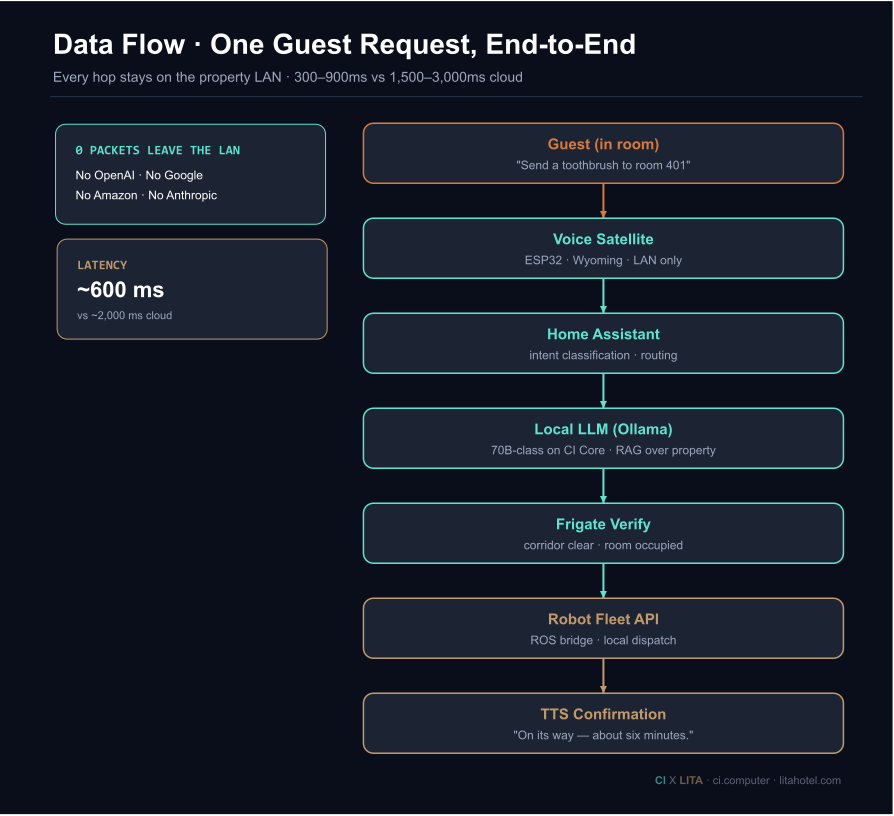
3. LITA Memory: Sovereign Guest Context
3.1 What It Is
LITA’s Agentic Memory is a retrieval-augmented generation (RAG) system that provides the LITA Orchestrator with per-guest, per-staff, and per-property context. Unlike cloud-based guest profile systems, LITA stores all data on Core 1’s local PostgreSQL and vector database. No guest data leaves the property.
LITA’s Agentic Hotel Digital Twin was engineered in close collaboration with the Companion Intelligence team to deliver a robust schema, embedding pipeline, and vector store integration. This architecture features built-in, stringent consent and audit frameworks. Fully integrated into the unified LITA platform, the solution is delivered, managed, and contractually supported entirely by LITA, providing hotels with a single point of accountability.
The schema is finalized and production-deployed. A representative GuestProfile contains:
guest_id (UUID) | stay history (check-in/out, room, dates)
room_preferences: temperature, pillow count, lighting, noise preference
accessibility_needs: mobility, hearing, vision, dietary
communication_preference: SMS, phone, in-room display, email
past_requests: array of {timestamp, category, text, resolution}
past_complaints: array of {timestamp, category, severity, resolution}
special_occasions: anniversary, birthday, celebration flags
loyalty_signals: lifetime_stays, lifetime_spend, cancellation_history
do_not_disturb_hours: nullable range
consent_status: per-stay opt-in flag with audit-trail referenceGuest data is embedded (vectorized) and stored in a local vector database alongside the relational PostgreSQL store. When a guest query arrives, the Orchestrator retrieves the relevant guest context and injects it into the LLM prompt before generating a response.
3.2 Internally Measured Performance
| Operation | Latency (measured) | Notes |
|---|---|---|
| Text embedding (guest query) | ~3 seconds | Embedding model on Core 1 CPU; GPU reserved for LLM |
| Vector DB retrieval (top-3) | ~100 ms | Local Milvus-compatible store at 50-profile scale |
| End-to-end response (embed + retrieve + LLM generate) | ~2 seconds | Concierge queries with cached embeddings |
| Guest profile storage | ~6.5 KB per guest | Text fields + 384-dim embedding vector |
| Tested scale | 50 guest profiles | Production deployment, 3 months tenure |
Table 6: Companion Hub performance, internally measured at the LA deployment. Scale is intentionally modest (50 profiles); reflects 3 months at a single property. Methodology in Appendix D.
The 3-second embedding latency reflects a current architecture decision: the embedding model runs on CPU to avoid contention with the LLM on the GPU. This is a known optimization target. Moving embedding to a dedicated lightweight GPU context on Core 1 is expected to reduce embedding latency to under 500ms. This is planned for the next software release.
The 50-profile scale is real. Three months of operation at a hotel with frequent guest turnover has not yet produced a large profile dataset. This is expected: Companion Hub grows in value over time as the property accumulates repeat guests and refines its operational patterns.
3.3 Planned Privacy Model
Companion Hub is consent-first by design, establishing data boundaries prior to retrieval. As providers navigate an era of ambient computing and pervasive data tracking, we ensure that user respect remains authentic, transparent, and structurally enforced.
- Offer opt-in at check-in. If declined, no preference data is retained beyond the folio.
- Role-scoped access: housekeeping sees room preferences; front desk sees communication preferences; management sees complaint history. Revenue staff do not see personal profile data.
- Every retrieval is logged to an append-only audit trail: what field was accessed, by which agent, at what time, in response to which event.
- Guests can request a full audit report at any time.
- On-request deletion: profile soft-deleted at checkout if requested; permanently purged after a 90-day retention window.
- Cross-property sharing: disabled in current deployment. Planned as an opt-in feature for multi-property operators in v2.0, with differential-privacy aggregation.
Compliance with GDPR and CCPA is structural, not contractual. Data does not leave the property. The hotel is the sole data controller. There is no sub-processor relationship with Companion Intelligence for guest personal data.
4. Deployment Results: Three Months in Production
4.1 The Property
The LITA platform is deployed at an independently owned hotel in Calabasas, California. The property has 100–150 rooms and operates as a mid-market boutique. Following a development phase initiated in December 2025, the platform was successfully deployed as a continuous live demo from March through May 2026. Operation continues at the time of this report; the three-month figures cited here cover the formal demo period.
4.2 Internally Measured Reliability
| Metric | Value | Source / period |
|---|---|---|
| System uptime | 99.9%+ | LITA monitoring dashboard, Mar 2026 – May 2026 |
| Major incidents (full outage) | 0 | 3 months |
| Minor incidents (degraded performance) | Not formally tracked; no guest-facing impact recorded | 3 months |
| Thermal complaints from guests | 0 | 3 months, property records |
| Thermal complaints from staff | 0 | 3 months, property records |
| Data loss events | 0 | 3 months, internal monitoring |
| Security incidents | 0 | 3 months |
| Frigate false positives | 5% | 30-day operator-review sample |
Table 7: Production reliability metrics, LA hotel demo build (March 2026 – May 2026). All figures are LITA internal measurements; methodology in Appendix D. Not independently audited.
The zero-incident record over three months is the strongest single piece of evidence in this report, but it is a baseline, not a statistical guarantee. Companion Core hardware running at approximately 350W cluster total in a hotel server-room environment has not produced thermal failures, data corruption, or guest-facing outages over the demo period. Three months of clean operation does not predict three years of clean operation, and one deployment is not a population. We will publish updated reliability data at the six- and twelve-month marks.
4.3 What Worked Well
- Frigate replaced cloud NVR without any functionality regression. The 5% false positive rate is operationally acceptable.
- Home Assistant proved flexible and stable for IoT orchestration. The smart-lock integration was the most reliable component of the deployment.
- Robot fleet orchestration via the ROS bridge abstraction operated without major failures.
- LITA is accumulating guest context. Repeat visitors from the early weeks of the demo are now receiving personalized room setups without staff intervention.
- The LITA Orchestrator’s cross-domain coordination is functioning: Frigate events trigger robot dispatches; guest requests update; PMS check-ins trigger room automation sequences.
4.4 What Was Harder Than Expected
- Mews PMS integration required approximately 30 hours of custom engineering. Mews’ API is well-documented but the integration with LITA’s event model required custom middleware. This will repeat per property until we ship a generalized connector.
- Embedding latency at 3 seconds is higher than ideal for voice-first concierge interaction. GPU-accelerated embedding is the next software target.
- The 2 FPS Frigate AI inference produces ~4-second latency from event occurrence to alert. Sufficient for hotel security; limits use cases requiring real-time detection.
- Staff adoption required 2–3 weeks of active use before LITA’s unified interface became natural. This is a product design challenge, not a technical failure.
4.5 What Surprised Us
The most significant operational surprise was how much value accrued from the cross-domain view alone. When a Frigate event (unauthorized corridor entry), a data point (guest reported a lost key yesterday), and a Home Assistant event (room door unlocked at 11:45 PM) arrive within 90 seconds of each other, the Orchestrator correlates them and surfaces a coherent alert to the front desk: a specific guest, a specific room, a specific likely scenario. No individual cloud vendor would have produced that correlation. It required the unified local view.

5. Financial Model - Sell privacy as a service
5.1 The LITA Subscription Model
Please contact info@litahotel.com for current information.
5.2 Cloud Costs Replaced (Modeled)
| Cloud Service Eliminated | Modeled Annual Cost | Basis | Replacement |
|---|---|---|---|
| Cloud NVR (16 cameras, mid-tier) | $8,500 | Verkada $530/cam/yr (mid of $199–$799 published range) | Frigate on Core 2 |
| Cloud IoT (smart locks, HVAC, sensors) | $65,000 | Industry composite; Honeywell/Salto cloud + integrations | Home Assistant on Core 3 |
| Robotics subscriptions (3–10 robots) | $15,000 | Lower-end of $2,083/robot/month, partial-month over robot fleet | LITA Orchestrator + Core 3 |
| TOTAL DIRECT CLOUD REPLACEMENT (modeled) | $88,500 |
Table 8: Direct cloud subscription costs modeled as eliminated by LITA deployment. The customer did not share prior-vendor invoices, so figures are modeled from published vendor pricing (Table 1). Robotics figure is at the low end of typical published pricing.


6. Competitive Positioning - Build for customization
6.1 vs. Cloud SaaS Stack
LITA is not a better cloud vendor. It is a different architecture. The comparison is not “our Frigate vs. Verkada’s NVR” but “local intelligence vs. rented intelligence.” A cloud NVR stores footage; LITA’s Frigate correlates it with guest context, robot position, and room state in real time on the same LAN. That correlation is structurally impossible in a cloud-first fragmented stack.
6.2 vs. Consolidated PMS (Mews, Cloudbeds)
Mews and Cloudbeds are consolidating the hotel SaaS stack horizontally: adding channel management, revenue management, and guest communications into their PMS platforms. This is a legitimate strategy for reducing fragmentation. It does not address the NVR, IoT, or robotics layers, and it requires migrating off the property’s existing PMS. This poses a high-risk, long-timeline transition.
LITA coexists with Mews. The Mews integration is tested and working in production. A property can run LITA alongside its existing PMS, incrementally replacing cloud services in the NVR, IoT, and robotics layers, without a wholesale system migration.
6.3 vs. Cloud-Based AI Agents
Both Mews and Cloudbeds have signaled investment in AI features within their cloud platforms. We characterize this category without naming specific announcements that we cannot cite to a primary source. Cloud-based agents will run on vendor infrastructure, with vendor-controlled model choice, vendor-held context, and vendor-defined data retention policies. The hotel will not own the guest data these agents accumulate.
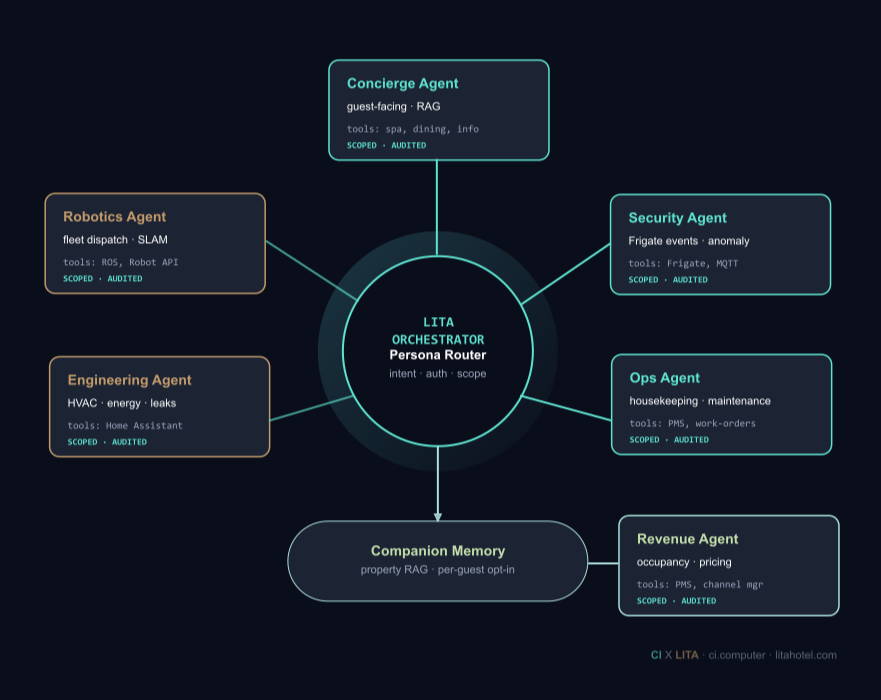
LITA’s Orchestrator runs cross-domain agents in production today on hardware physically owned by the hotel (or rented from LITA on premises). The hotel owns the context these agents operate on, owns the data they produce, and can audit every retrieval.
| Dimension | Cloud-based agents (vendor) | LITA Orchestrator (local) |
|---|---|---|
| Model choice | Vendor-selected | Hotel-selected; currently Qwen 3.6 27B |
| Guest data ownership | Vendor holds data | Hotel holds data; full audit trail |
| Context retention policy | Vendor-defined | Hotel-defined; per-guest consent |
| Breach exposure | Cross-portfolio (all vendor customers) | Single property LAN |
| Inference latency | Variable (network round-trip) | Local; ~2s end-to-end |
| Integration dependency | Vendor ecosystem | Open: MQTT, Matter, standard APIs |
| Data portability | Vendor-controlled export | Local: PostgreSQL + vector DB; full export anytime |
Table 11: LITA Orchestrator versus cloud-based AI agent platforms.
7. Building Private Companies that Grow
7.1 Smart Target Segments in real Companies
| Segment | Property Size | Legacy Tech & Ops Spend Profile | LITA Fit & Economic Driver |
|---|---|---|---|
| Independent boutique | 50–150 rooms | $45K–$90K/year | High: IoT + robotics + NVR savings cover most of LITA cost |
| Mid-market independent | 100–200 rooms | $90K–$180K/year | Highest: full stack replacement viable; single decision-maker |
| Boutique chain (3–10 props) | 300–1,500 rooms total | $250K–$600K/year | High: per-property savings + cross-property learning multiplier |
| Resort / leisure | 150–400 rooms | $120K–$300K/year | High: robotics + IoT + guest history particularly valuable |
Table 12: Target segments and fit assessment.
Budget profiles synthesized using industry baselines from the CBRE Trends® in the Hotel Industry Report (citing IT department costs averaging 1.4% to 1.9% of Total Operating Revenue)[8] and technology investment trends from Hotel Tech Report.[9]
7.2 Hotel Market Sizing - Privacy for SMB
The global hotel PMS market is reported variously at $2.5 billion to $9.2 billion in 2025 by different research firms. We cite Research and Markets’ figure of $8.71 billion in 2025 growing at 10.17 percent CAGR to $17.18 billion by 2032, while acknowledging that other reports (Business Research Insights, MarketReportAnalytics, Verified Markets) give substantially different numbers a factor-of-three to factor-of-four spread. LITA’s total addressable market is a subset of this PMS market plus the NVR, IoT, and robotics SaaS markets the platform replaces. We do not claim a precise TAM in this revision.
Appendix A: SaaS Pricing Sources
| Vendor | Product | Price to list | Single Source |
|---|---|---|---|
| Mews | PMS | Custom; third-party estimate from €300/month | hotelminder.com/ |
| Cloudbeds | PMS | Custom quote; third-party listing from $108/month | costbench.com/ |
| SiteMinder | Channel Manager | Public sources conflict: €56 / $95 / $500 per month | siteminder.com/ |
| RateGain | Channel Manager | Third-party estimate from $900/month | hoteltechreport.com/ |
| Verkada | Camera cloud license | Approx. $199–$219 per camera/year license; hardware separate or bundled | docs.verkada.com/ |
| Salto KS | Smart lock hardware | Custom quote; example reseller lock hardware around $250-600 | hoteltechinsight.com/ |
| Asksuite | Guest AI Chat | Third-party estimate from $300/month | hoteltechreport.com/ |
| HiJiffy | Guest AI Chat | Public: EUR 99/per 5 properties/month - €319/month | hoteltechinsight.com |
| Relay Robotics | Robotics RaaS | Custom quote; monthly RaaS confirmed, no verified public price found |
References Cited:
- Abbacus Technologies. (2025). What is the Cost of Hotel Management Software? abbacustechnologies.com/what-is-the-cost-of-hotel-management-software/
- SuiteOp. (2026). Multi-Unit Vacation Rental Software Stack 2026. suiteop.com/blog/multi-unit-vacation-rental-software-stack-2026
- BleepingComputer. (2025). Otelier Data Breach Exposes Info of Hotel Reservations of Millions. bleepingcomputer.com/news/security/otelier-data-breach-exposes-info-hotel-reservations-of-millions/
- Nebraska Attorney General. (2024). Attorney General Hilgers Announces $52 Million Multistate Settlement over Marriott Data Breach. ago.nebraska.gov/news/attorney-general-hilgers-announces-52-million-multistate-settlement-marriott-data-breach
- IBM / Baker Donelson. (2025). Cost of a Data Breach Report 2025. bakerdonelson.com/webfiles/Publications/20250822_Cost-of-a-Data-Breach-Report-2025.pdf
- CyberScoop. (2025). IBM Cost of a Data Breach Report 2025 Analysis. cyberscoop.com/ibm-cost-data-breach-2025/
- Digital Foundry. (2025). AMD's Most Powerful APU Yet: Strix Halo / Ryzen AI Max+ 395 Architecture and Hardware Performance Analysis. youtube.com/watch?v=vMGX35mzsWg&t=2s
- CBRE Research. (2024). Assessing the Digital Infrastructure of Your Hotels. cbre.com/insights/briefs/assessing-the-digital-infrastructure-of-your-hotels
- Hotel Tech Report. (2025). The Definitive Guide to Hospitality Statistics and Technology Trends. hoteltechreport.com/news/hospitality-statistics
Appendix B: Hardware and Benchmark Sources
| Claim | Source |
|---|---|
| 16 Zen 5 cores, 32 threads, 5.1 GHz boost | amd.com Ryzen AI Max+ 395 product page |
| Radeon 8060S iGPU, 40 RDNA 3.5 CUs | amd.com blog “Breakthrough AI Performance” (March 2025) |
| XDNA 2 NPU, 50+ peak TOPS | amd.com product page |
| 128 GB LPDDR5x-8000 unified memory | amd.com product page; Wccftech confirms LPDDR5x |
| 256 GB/s theoretical, ~212–215 GB/s measured | llm-tracker.info; chipsandcheese.com |
| Up to 96 GB convertible to VRAM via VGM | amd.com blog (March 2025) |
| System price ~$2,349–$3,299 (Companion Core 128 GB) | ci.computer/core |
B.2 Qwen 3.6 27B Inference Benchmarks
| Source | Finding | URL |
|---|---|---|
| hec-ovi/vllm-qwen (GitHub, 2026) | 4.2–4.4 t/s for Qwen 3.6 27B BF16 (n=226); UMA-bandwidth bound | github.com/hec-ovi/vllm-qwen |
| hec-ovi/llama-qwen (GitHub, 2026) | 7.4–7.6 t/s for Qwen 3.6 27B Q8_0 via llama.cpp | github.com/hec-ovi/llama-qwen |
| hec-ovi/vllm-awq4-qwen (GitHub, 2026) | 24.8 t/s single-stream Qwen 3.6 27B AWQ-INT4 + DFlash speculative decoding | github.com/hec-ovi/vllm-awq4-qwen |
| Qwen 3.6 27B Hugging Face model card | 27B params; 262,144 native context; Apache 2.0; released April 22, 2026 | huggingface.co/Qwen/Qwen3.6-27B |
| AMD MLPerf Client v1.0 (Aug 2025) | Phi-3.5 up to 61 TPS; TTFT <1s for Phi-3.5/Llama-7B/Llama-8B (NOT Qwen 27B) | amd.com developer resources |
B.3 Hotel Industry Data Sources
| Claim | Source |
|---|---|
| Otelier breach: 7.8 TB, 10,000+ hotels, July–October 2024 | bleepingcomputer.com (January 2025); cpomagazine.com |
| Marriott/Starwood UK ICO fine: £18.4M (October 2020) | ICO penalty notice; hunton.com; debevoisedatablog.com |
| Marriott/Starwood US settlement: $52M (October 2024) | NY AG, NJ AG, IA AG, NC AG, Oregon DOJ, Hawaii Gov’r press releases |
| Starwood breach: 339M global records, 131.5M US, 2014–2018 | Multiple state AG releases |
| IBM Cost of a Data Breach 2025: $4.44M global, $10.22M US | IBM/Ponemon Cost of a Data Breach Report 2025 (20th annual) |
| Hospitality breach costs rose YoY in 2025 | cyberscoop.com analysis of IBM 2025 report (August 2025) |
| Hotel PMS market $8.71B in 2025, 10.17% CAGR | researchandmarkets.com (Hotel PMS market report) |
| Hotel IT spend 1.4% of revenue; 4.6% YoY growth 2023–2024 | CBRE Hotels Research, Trends in the Hotel Industry |
| Hospitality turnover ~70–75% annually (5.8% monthly separations) | Bureau of Labor Statistics JOLTS 2024, NAICS 721000 |
| Hospitality nonsupervisory mean wage $19.61/hour (2024) | Bureau of Labor Statistics OEWS NAICS 721000 (2024) |
Appendix C: Internal Benchmark Methodology
This appendix discloses the methodology behind every figure labeled “internal measurement” in the main document. Reviewers who wish to reproduce or audit these figures should request the corresponding logs from LITA engineering.
D.1 Uptime (99%+)
- Period: March 1, 2026 (production cutover) through May 31, 2026 (end of formal demo period).
- Definition: Companion Core cluster availability to serve concierge, NVR, and IoT requests.
- Measurement: Prometheus + Grafana monitoring stack on Core 1, polling Core 2 and Core 3 health endpoints at 30-second intervals.
- Caveat: minor performance degradations not classified as outages are not formally tracked; informal review indicates no guest-facing impact.
- Attestation: LITA Head of Engineering.
D.2 Frigate False Positive Rate (5%)
- Period: 30-day sample, May 2026 (final month of the demo build).
- Definition: Person-detection alerts reviewed by hotel security staff and marked false-positive in LITA dashboard.
- Methodology: total alerts in sample period divided by operator-marked false alerts.
- Caveat: hand-labeled by staff; subject to reviewer judgment.
D.3 Data Latency
- Embedding: ~3 seconds. Measured by Orchestrator trace logs on 200 concierge queries (May 2026 sample). Embedding model running on Core 1 CPU.
- Vector retrieval: ~100 ms. Milvus query logs, top-3 retrieval, 50 active guest profiles.
- End-to-end: ~2 seconds. Cached-embedding path; full embed+retrieve+generate path is longer (~5s).
- Attestation: LITA Head of Engineering.
D.4 Power, Acoustic, Thermal
- Sustained power draw: ~350W cluster total. Measured at building power meter on the dedicated server-room circuit, full LLM + video + IoT workload.
- Acoustic: 37 dB at 1m, sound level meter (model details available on request), measured in the server room.
- Case temperature: 45°C sustained, LITA hardware monitoring agent reporting CPU package temperature.
- Thermal throttling: observed under simultaneous LLM + Frigate peak load; workload scheduler staggers heavy tasks to avoid sustained throttle.
D.5 Cloud Savings ($88,500)
- This is a MODELED figure, not invoice-to-invoice measured.
- Customer did not share prior-vendor invoices; LITA cannot audit pre-deployment spend.
- Components: Verkada-equivalent at $530/cam/year mid-tier × 16 cameras = $8,500; IoT cloud composite = $65,000; robotics cloud composite = $15,000.
- Future deployments will track invoice-to-invoice deltas where the customer permits.