Introducing the Just In Case Project
A Dedicated Knowledge Tool for Tough Times
When disaster strikes, panic follows confusion — and confusion starts when information disappears.
At Companion Intelligence, we’re building personal intelligence that works even when the world doesn’t. Secure. Contextual. Offline. Yours.
Because sometimes “just Google it” isn’t an option.
The Problem
We’ve built our lives around being connected — to 911, to the cloud, to search engines.
But what happens if those lifelines disappear for a day? Or a week?
No phone signal. No power grid. No Internet.
Just you, your people, and the moment that tests your plan.
The Solution
The Just In Case Project is our answer — a curated, offline digital library backed by AI.
It’s designed to eventually help people stay informed, capable, and calm when systems fail.
Think of it as a knowledge kit you can trust in any scenario:
Emergency medicine and first aid
Fire and evacuation plans
Food and water safety
Local hazard guides
Off-grid survival and communication basics
All searchable. All offline. All yours.
How It Works
The JIC dataset lives locally, not in the cloud, with an AI that helps you plan, prepare, and practice. It can quiz you on the basics, talk to you in your own language, and help keep your resources ready.
Why It Matters
Good planning isn’t about fear.
It’s about self-reliance, awareness, and care — for yourself, your loved ones, and your community.
Because intelligence should never go offline. Join us as we release the Just In Case dataset — the knowledge you’ll wish you had, already in your hands, private, secure, and searchable.
JIC is a free project from the team at Companion Intelligence. The knowledge datasets included come for open-source providers. If you would like to contribute to growing this important dataset, please feel free to join us here.
This is a work in progress and we welcome your participation. Currently, we do not recommend relying solely on this product in an emergency situation.
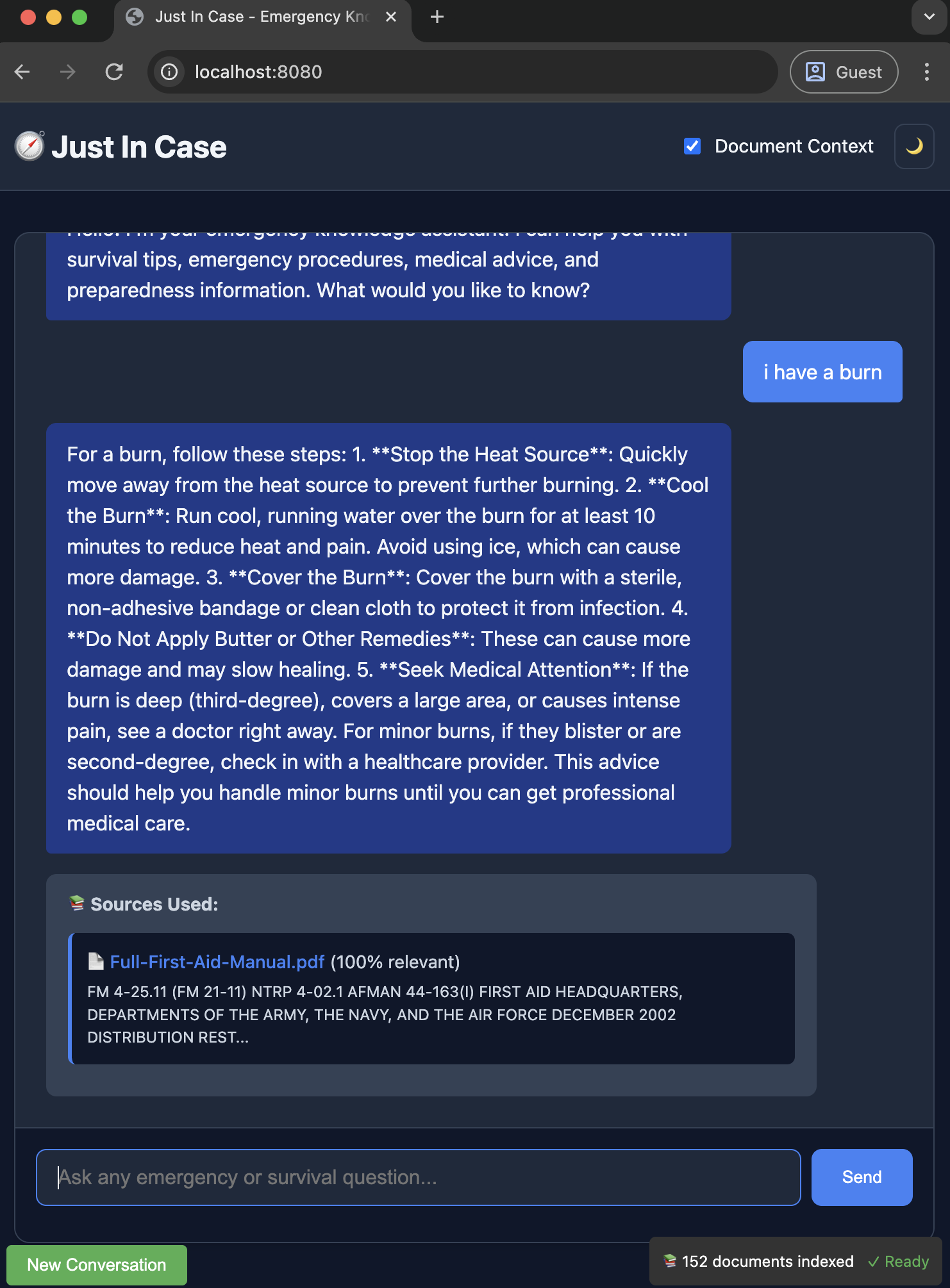
Offline Emergency Knowledge Search
The Challenge: Conversational Search
Many of us have some kind of plan for a crisis; a flashlight in a drawer, extra food supplies, water, cash, a map of community resources, a muster-point, a group of friends to rely on. We're generally aware of region specific risks, tornados, tsunamis, forest fires - but what's missing is actionable instant information - the stuff that fills in the gaps in the larger plan.
For better or worse we now heavily rely on conversational search tools such as ChatGPT, Claude, Google AI and other online resources. Even for small questions such as "how do you wire up rechargeable batteries to a solar panel?" or "what is the probable cause of a lower right side stomach pain?".
The problem is that these services are often cloud based, and not always at our fingertips. We don't realize that during an emergency, the very thing we rely on may not be there. To get a feel for this try turn off your phone and the Internet for just one day.
The fact is that there's a real difference between the difficulty of trying to read through a book on how to treat a burn during an emergency, versus getting some quick help or counsel, conversationally, right away, or at least getting some quick guidance on where to look for more details. What would you do if the internet went down? Or even just an extended power outage? What is your families plan for region-specific threats such as tornadoes, tsunamis, or forest fires? Many of us have some kind of plan; a flashlight in a drawer, extra food supplies, water, cash, a map of community resources, a muster-point.
The world has changed, we now heavily rely on tools such as ChatGPT, Claude, Google and other online resources. Even for small questions such as "how do you wire up rechargeable batteries to a solar panel?" or "what is the probable cause of a lower right side stomach pain?". The thing most of us rely heavily on information itself, and that information is not always at our fingertips.
Validating a tool like this raises many questions. Who are typical users of the dataset? What are typical scenarios? Can we build a list of typical questions a user may ask of the dataset? Can we have regression tests against the ability of the dataset to resolve the queries? Are there differences in what is needed for short, medium or extended emergencies or extended survival situations? In this ongoing project we'll try to tackle these and improve this over time.
Conversational interfaces can bridge a gap - at the very least providing search engine like guidance on how to get more information quickly.
Proposed Approach
The goal of the JIC project is to provide offline information:
a wide variety of documents and reference material
possibly later also live maps of recent regional data
interactive intelligence / LLM
The novel feature (as mentioned) that seems the most useful for non-technical users is a conversational interface (chatBot) to access emergency data in a conversational manner.
To tackle that, the CI team proposed an offline LLM driven knowledge corpus, collecting documents, and providing actionable intelligence over them. This is a variation of common corporate RAG style document stores with query engines, with the exception that the JIC project must run in an offline context.
Classical Offline Knowledge Sources
There are many excellent existing efforts to provide offline emergency knowledge - and those are great fuel for the LLM. This includes survival guides, medical references, even agricultural know-how and engineering resources, as well as broader educational materials like offline Wikipedia, open textbooks, art and humanities. There are also many challenges here in terms of deciding what to curate, what kinds of ongoing aggregation are needed (prior to a catastrophe) and how to organize that knowledge statically.
Validating a tool like this raises many questions. Who are typical users of the dataset? What are typical scenarios? Can we build a list of typical questions a user may ask of the dataset? Can we have regression tests against the ability of the dataset to resolve the queries? Are there differences in what is needed for short, medium or extended emergencies or extended survival situations? Here are a few documents that we used to ground our thinking so far:
Design Rationale
The general topic of ingesting large amounts of data and making that data conversationally accessible (by prompting the llm with appropriate context) is a well known one, and this proof of concept effectively is an implementation of that larger thesis. Here are a few details on lower level technical aspects:
The CI Team’s Approach
Components
We've tried a variety of approaches to optimize the JIC project for clarity and speed. Some of our favorite tools included Ollama, python, N8N. Our current stack is turning out to be simply C++ with what feels like 'direct to the metal' interactions with the tools we need:
ComponentRole
🧠
Llama.cppLLM loader (e.g.llama3)📄
Apache TikaPDF-to-text extractor🔍
FAISSVector search over parsed PDF chunks🌐
C++ ServerSimple API + minimal HTML frontend
Quickstart on GitHub
For the technically literate, you can now jump straight in and download your own FREE Just In Case project.
For CI clients, don’t forget to include the JIC project installer at check-out.
If you have any questions, please reach out to us at hello@companionintelligence.com